코드 프레소 [파이썬으로 배우는 Pandas ] 강의 내용 정리
# Pandas...?
Pandas는 데이터 분석을 위한 도구로 사용된다. Python 라이브러리이며, 2차원의 데이터로부터 의미를 도출하는 전과정에 필수적이다.

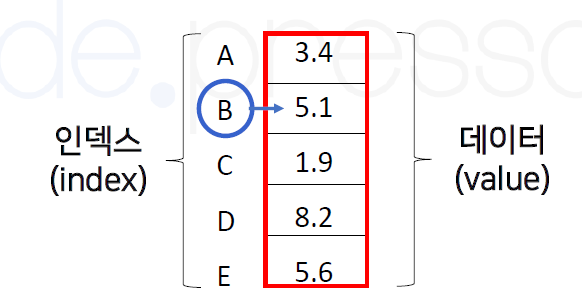
Pandas의 자료구조로는 위의 그림과 같이 Series와 DataFrame이 있다.
Series의 특징은 아래와 같다.
- 1차원의 배열구조이다.
- 인덱스를 통한 데이터 조회 및 접근이 가능하다.
- 동일한 데이터 타입의 값을 저장한다.
DataFrame의 특징을 정리하면 아래와 같다.
- 행과 열을 가진 2차원이다.
- 데이터와 행/열에 대한 인덱스가 저장된다.
- 각 컬럼은 서로 다른 데이터 타입으로 구성될 수 있다.
- 1개의 column은 Series객체로 구성된다.

DataFrame은 다양한 형태의 data가 저장될 수 있다.
(Series 객체, 중첩된 딕셔너리 객체, 딕셔너리 리스트, 리스트, 튜플 리스트,ndarray...etc)
Python의 Pandas 라이브러리의 자료구조인 Series, DataFrame을 API Reference를 참고하여 이해하고 예시코드와 함께 자료구조 활용을 실습해본다.
# API Reference
# Series
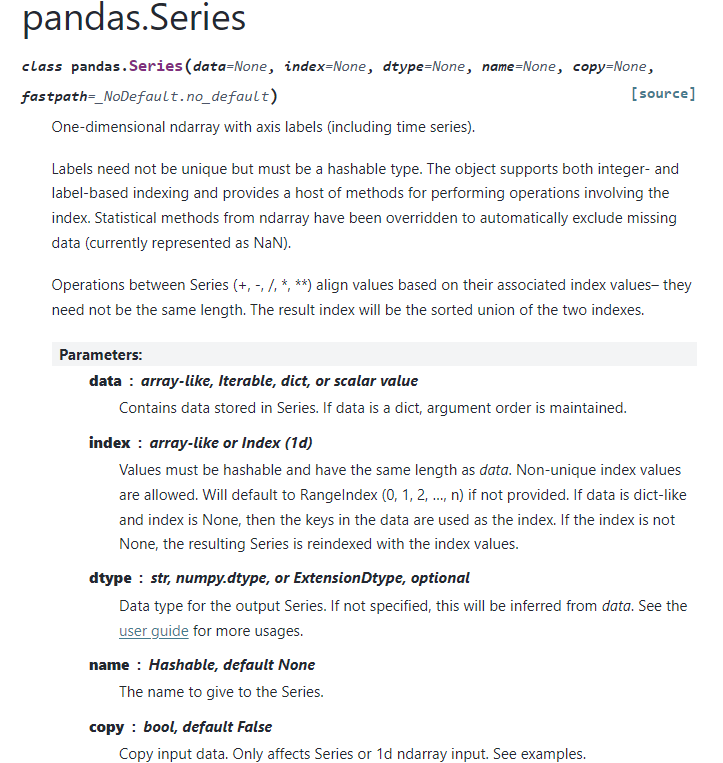
API Reference :: pandas.Series
# parameter 정리
- data :Series에 저장될 데이터를 의미한다. array-like, Iterable, dict, 또는 scalar 값일 수 있다. 만약 data가 dict일 경우, 인수의 순서는 유지된다.
- index : array-like 또는 Index (1차원)이다. 값은 해시 가능해야 하며, data와 동일한 길이를 가져야 한다. 중복된 인덱스 값도 허용된다. 인덱스를 제공하지 않으면 기본적으로 RangeIndex(0, 1, 2, …, n)가 설정된다. data가 dict 형태이고 index가 None일 경우, dict의 키가 인덱스로 사용된다. 인덱스가 제공되면, 결과 Series는 해당 인덱스 값으로 재인덱싱된다.
- dtype : str, numpy.dtype, 또는 ExtensionDtype으로 선택 가능하며, 선택 사항이다. 지정되지 않으면 data에서 데이터 타입이 추론된다. 다양한 사용 방법은 사용자 가이드를 참조한다.
- name : Series에 부여할 이름으로, 기본값은 None이다.
- copy : bool 타입으로, 기본값은 False이다. 입력 데이터를 복사할지 여부를 결정하며, 이는 Series 또는 1차원 ndarray 입력에만 영향을 준다.
# 예시코드
# Series 객체 생성
import pandas as pd
year = ["2019", "2020", "2021", "2022"]
result = pd.Series(data = year)
print('\nType',type(result))
print(result)
#코드에서 index를 지정하지 않았기에 정수 0부터 시작되는 인덱스가 생성된다.
Type <class 'pandas.core.series.Series'>
0 2019
1 2020
2 2021
3 2022
dtype: object
# Series 주요 속성
import pandas as pd
year = ["2019", "2020", "2021", "2022"]
result = pd.Series(data = year)
print('Index : ',result.index)
print('Data : ',result.values)
print('Dtype : ',result.dtype)
print('Shape : ',result.shape)Index : RangeIndex(start=0, stop=4, step=1)
Data : ['2019' '2020' '2021' '2022']
Dtype : object
Shape : (4,)
# Series 객체 및 인덱스 이름 지정
import pandas as pd
year = ["2019", "2020", "2021", "2022"]
result = pd.Series(data = year)
result.name = 'Year'
result.index.name ='No.'
print("\n",result)
idx = ['a','b','c','d']
result = pd.Series(data=year, index=idx,name='Year')
print("\n")
print(result) No.
0 2019
1 2020
2 2021
3 2022
Name: Year, dtype: object
a 2019
b 2020
c 2021
d 2022
Name: Year, dtype: object
# Series : 딕셔너리로 Series 객체 생성
import pandas as pd
score = {'Kim' : 53, 'Han':39, 'Jung':90, "Choi":100}
result = pd.Series(data=score, name='Score')
print(result)Kim 53
Han 39
Jung 90
Choi 100
Name: Score, dtype: int64# DataFrame
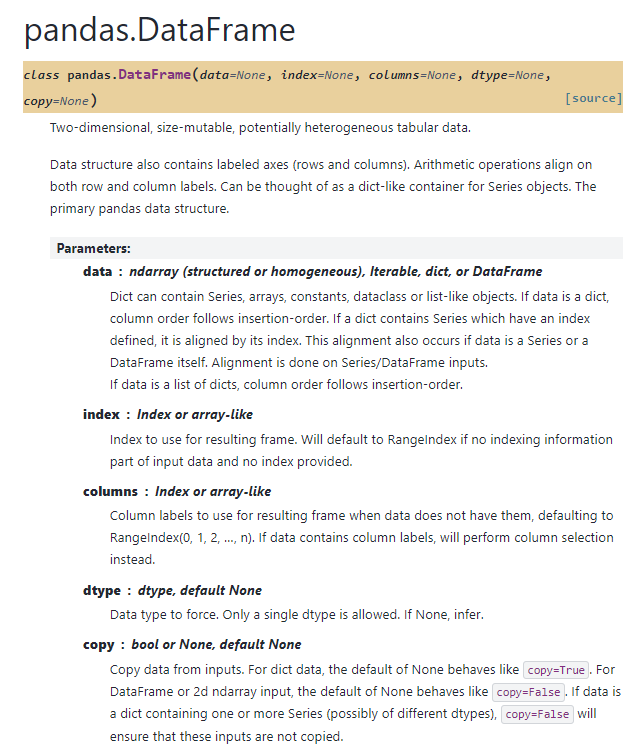
API Reference :: pandas.DataFrame
# parameter 정리
- data : ndarray(구조화 또는 단일형), Iterable, dict 또는 DataFrame을 의미한다. dict는 Series, 배열, 상수, dataclass 또는 list-like 객체를 포함할 수 있다. 만약 data가 dict일 경우, 열의 순서는 삽입 순서를 따른다. dict가 인덱스가 정의된 Series를 포함하면, 해당 인덱스에 맞춰 정렬된다. 이 정렬은 data가 Series 또는 DataFrame일 때도 동일하게 적용된다. 정렬은 Series 또는 DataFrame 입력에서 수행된다. 만약 data가 dict 리스트인 경우, 열의 순서는 삽입 순서를 따른다.
- index : Index 또는 array-like 객체로, 결과 DataFrame에 사용할 인덱스이다. 입력 데이터에 인덱스 정보가 없고 인덱스를 따로 지정하지 않으면 기본적으로 RangeIndex가 사용된다.
- columns : Index 또는 array-like 객체로, 결과 DataFrame에 사용할 열 레이블이다. 데이터에 열 레이블이 없으면 기본값으로 RangeIndex(0, 1, 2, …, n)가 사용된다. 데이터에 열 레이블이 있을 경우, 해당 열을 선택하게 된다.
- dtype : 데이터 타입을 지정하는 옵션이며, 기본값은 None이다. 하나의 dtype만 허용되며, 지정하지 않으면 데이터에서 자동으로 추론된다.
- copy : bool 또는 None 값으로, 기본값은 None이다. 입력 데이터로부터 복사 여부를 결정한다. dict 데이터를 사용할 경우 기본값인 None은 copy=True로 동작하며, DataFrame이나 2차원 ndarray 입력의 경우 기본값은 copy=False로 동작한다.만약 dict가 여러 개의 Series를 포함하고 있고, copy=False가 설정되면 해당 입력은 복사되지 않는다.
# 예시코드
# Data Frame 객체 생성 :: 딕셔너리 객체 활용
import pandas as pd
score = {'name' : ['James', 'Emma','Alex','Tom'],
'score': [100, 95, 80, 85],
'grade': ['A','A','B','B']
}
df = pd.DataFrame(data=score)
print(type(df))
print(df)<class 'pandas.core.frame.DataFrame'>
name score grade
0 James 100 A
1 Emma 95 A
2 Alex 80 B
3 Tom 85 B
# DataFrame 주요 속성
import pandas as pd
score = {'name' : ['James', 'Emma','Alex','Tom'],
'score': [100, 95, 80, 85],
'grade': ['A','A','B','B']
}
df = pd.DataFrame(data=score)
print('Index: ', df.index)
print('Columns: ',df.columns)
print('Values: ')
print(df.values)
print('\nDtype: ')
print(df.dtypes)
print('Shape: ',df.shape)Index: RangeIndex(start=0, stop=4, step=1)
Columns: Index(['name', 'score', 'grade'], dtype='object')
Values:
[['James' 100 'A']
['Emma' 95 'A']
['Alex' 80 'B']
['Tom' 85 'B']]
Dtype:
name object
score int64
grade object
dtype: object
Shape: (4, 3)
'공부한 것들.. > Pandas' 카테고리의 다른 글
| Pandas 결측치 이해 및 결측치 처리 (2) | 2024.09.14 |
|---|---|
| Pandas 데이터 파일 읽기 (1) | 2024.09.14 |
| Pandas DataFrame 데이터 추가 및 삭제 (0) | 2024.09.13 |
| Pandas 데이터 조회 및 변경 (0) | 2024.09.13 |
| Pandas 수치형 데이터 & 범주형 데이터 활용 (0) | 2024.09.13 |



