코드 프레소 [파이썬으로 배우는 Pandas] 강의 내용 정리
# 데이터 파일 읽기..?
Pandas 라이브러리에서는 다양한 포맷의 파일에 대한 Reader/Writer 함수를 제공한다.
API Reference : Pandas IO tools

이 중 대표적으로 read_csv()와 read_excel() 2개의 함수에 대해 알아보겠다.
# csv 파일이란..?
CSV(Comma Seperated Values) 파일은 말 그대로 쉼표(comma)를 기준으로 데이터를 구분하여 저장된 파일을 의미한다.
예시 코드의 실습 데이터 셋(titanic.csv)을 살펴보면 아래와 같다.
https://www.kaggle.com/datasets/yasserh/titanic-dataset
Titanic Dataset
Titanic Survival Prediction Dataset
www.kaggle.com

# API Reference
# pandas.read_csv()
API Reference : pandas.read_csv()

너무 자세하게 정리하지 않고 Basic에 해당하는 내용만 정리해보겠다.
# parameter 정리
- filepath_or_buffer: 파일 경로, URL 또는 read() 메서드를 가진 객체. 경로는 문자열, pathlib.Path, 또는 py._path.local.LocalPath 형식이 가능하며, URL의 경우 http, ftp, S3 등의 위치도 지원한다. 또한 열려 있는 파일 객체나 StringIO 같은 객체도 가능하다.
- sep: 문자열로, 구분자를 지정한다. read_csv()의 기본값은 ',', read_table()의 기본값은 \t이다. sep이 None이면 C 엔진은 구분자를 자동으로 감지하지 못하지만, Python 파싱 엔진은 csv.Sniffer 도구를 사용해 자동 감지가 가능하다. 1글자보다 긴 구분자나 \s+와 다른 구분자는 정규 표현식으로 해석되며, Python 파싱 엔진을 강제로 사용하게 된다. 정규 표현식을 구분자로 사용하면 인용된 데이터를 무시할 수 있다. 예: '\\r\\t'.
- delimiter: 구분자를 지정하는 sep의 대체 인자이다. 기본값은 None.
- delim_whitespace: 공백을 구분자로 사용할지를 지정하는 부울 값. 기본값은 False이며, True로 설정하면 sep='\s+'와 동일한 효과를 갖는다. 이 옵션이 True로 설정된 경우 delimiter 인자에 값을 지정하지 않아야 한다.
# 예시코드
import pandas as pd
url = 'https://codepresso-online-platform-public.s3.ap-northeast-2.amazonaws.com/learning-resourse/titanic_train.csv'
titanic_df = pd.read_csv(url)
print(type(titanic_df))
print(titanic_df.head(1))
print(titanic_df.info())#head(1)을 통해 맨 위의 한 개의 행에 대한 데이터가 출력되는 것을 볼 수 있다.
<class 'pandas.core.frame.DataFrame'>
PassengerId Survived Pclass ... Fare Cabin Embarked
0 1 0 3 ... 7.25 NaN S
#df.info()를 호출하여 DataFrame에 저장된 데이터셋에 대한 정보를 출력한다.
[1 rows x 12 columns]
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
None
# pandas.read_excel()
API Reference : pandas.read_excel()
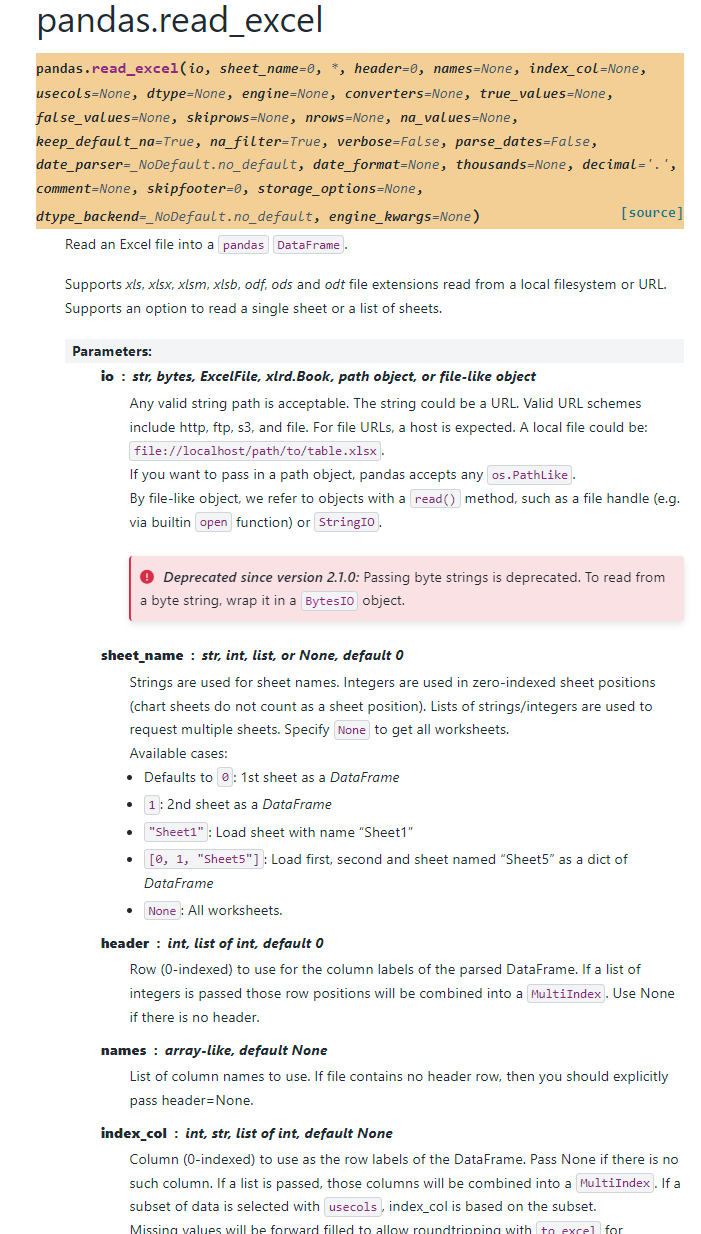
위의 링크를 통해 들어가 보면 캡쳐 사진보다 더 많은 parameter에 대한 정보를 알 수 있다.
# paramter 정리
- io : str, bytes, ExcelFile, xlrd.Book, path object, 또는 file-like object: 유효한 문자열 경로. 문자열은 URL일 수 있으며, 지원되는 URL 스킴에는 http, ftp, s3, file 등이 포함된다. 로컬 파일의 경우, file://localhost/path/to/table.xlsx 형식을 사용한다. os.PathLike 객체도 사용할 수 있으며, read() 메서드를 가진 객체(파일 핸들이나 StringIO 등)도 가능하다. 버전 2.1.0부터는 바이트 문자열을 넘기는 것이 더 이상 권장되지 않으며, 이를 사용하려면 BytesIO로 감싸야 한다.
- sheet_name: 문자열, 정수, 리스트, 또는 None. 문자열은 시트 이름, 정수는 0부터 시작하는 시트 위치를 나타낸다. 리스트는 여러 시트를 요청할 때 사용되며, None은 모든 시트를 가져온다.
- header: 0부터 시작하는 정수 또는 정수의 리스트. DataFrame의 열 이름으로 사용할 행 번호를 지정한다. 여러 행을 MultiIndex로 결합하려면 정수 리스트를 넘긴다. 헤더가 없으면 None을 넘긴다.
- names: 배열 형태로, 열 이름을 지정한다. 파일에 헤더 행이 없으면 header=None을 명시적으로 넘겨야 한다.
- index_col: 0부터 시작하는 정수, 문자열 또는 리스트. DataFrame의 행 레이블로 사용할 열을 지정한다. 리스트를 넘기면 해당 열들이 MultiIndex로 결합된다. usecols로 데이터를 선택한 경우, index_col은 해당 열에 기반한다.
- usecols: 문자열, 리스트 또는 함수. 파싱할 열을 지정한다. 문자열로 Excel 열 문자나 열 범위를 지정할 수 있고, 리스트로 열 번호나 열 이름을 지정할 수 있다. 함수는 각 열 이름에 대해 실행되며, 함수가 True를 반환하는 경우 그 열이 파싱된다.
- dtype: 열에 적용할 데이터 타입을 지정한다. 예: {'a': np.float64, 'b': np.int32}. 데이터를 해석하지 않고 저장된 그대로 유지하려면 object를 사용한다. converters를 지정한 경우, dtype 변환 대신 이를 적용한다.
- engine: 사용할 Excel 엔진을 지정한다. openpyxl, calamine, odf, pyxlsb, xlrd 중 하나를 선택할 수 있다. 지정하지 않으면 파일 형식에 따라 자동으로 선택된다.
- converters: 특정 열의 값을 변환하는 함수의 사전. 키는 정수 또는 열 레이블이 될 수 있으며, 값은 Excel 셀 내용을 변환하는 함수다.
- true_values / false_values: True 또는 False로 간주할 값의 리스트.
- skiprows: 건너뛸 행 번호 또는 행의 수. 호출 가능 객체를 넘기면 해당 함수가 행 인덱스를 기준으로 실행되며, 반환 값이 True이면 해당 행이 건너뛰어진다.
- nrows: 파싱할 행의 수를 지정한다.
- na_values: NA/NaN으로 인식할 추가 문자열을 지정한다. 사전을 넘기면 열마다 다르게 설정할 수 있다.
- keep_default_na: 기본 NA 값을 포함할지 여부를 지정한다.
- na_filter: NA 값(빈 문자열과 na_values로 지정된 값)을 감지할지 여부를 지정한다.
- verbose: NA 값이 포함된 비숫자 열의 개수를 표시할지 여부를 지정한다.
- parse_dates: 날짜로 파싱할 열을 지정한다. True, 열 번호나 이름의 리스트, 열 번호의 리스트 리스트, 또는 사전 형식으로 설정할 수 있다.
- date_parser: 문자열을 날짜로 변환할 함수. 기본적으로 dateutil.parser.parser가 사용된다.
- date_format: parse_dates와 함께 사용하면 해당 형식으로 날짜를 파싱한다.
- thousands: 숫자로 파싱할 때 사용하는 천 단위 구분 기호.
- decimal: 숫자로 파싱할 때 사용하는 소수점 기호.
- comment: 주석을 나타내는 문자열. 지정한 문자열 이후부터 그 줄의 끝까지의 데이터는 무시된다.
- skipfooter: 건너뛸 마지막 행의 수를 지정한다.
- storage_options: 특정 저장소 연결을 위한 추가 옵션. 예: 호스트, 포트, 사용자 이름, 비밀번호 등.
- dtype_backend: 결과 DataFrame에 적용할 백엔드 데이터 타입. numpy_nullable(기본값) 또는 pyarrow 중 하나를 선택할 수 있다.
- engine_kwargs: Excel 엔진에 전달할 임의의 키워드 인자.
# 예시 코드
import pandas as pd
url = 'https://codepresso-online-platform-public.s3.ap-northeast-2.amazonaws.com/learning-resourse/python-data-analysis/students_score.xlsx'
print('\nRead students_score.xlsx')
sample_df = pd.read_excel(url)
print(sample_df)pandas.read_excel()을 통해 excel파일을 불러오면 아래와 같은 결과가 출력된다.
Read students_score.xlsx
Jessi 20 100 A python
0 Emma 24 95 A java
1 Alex 23 80 B python
2 Jessi 20 85 B c
3 Tom 27 97 A java
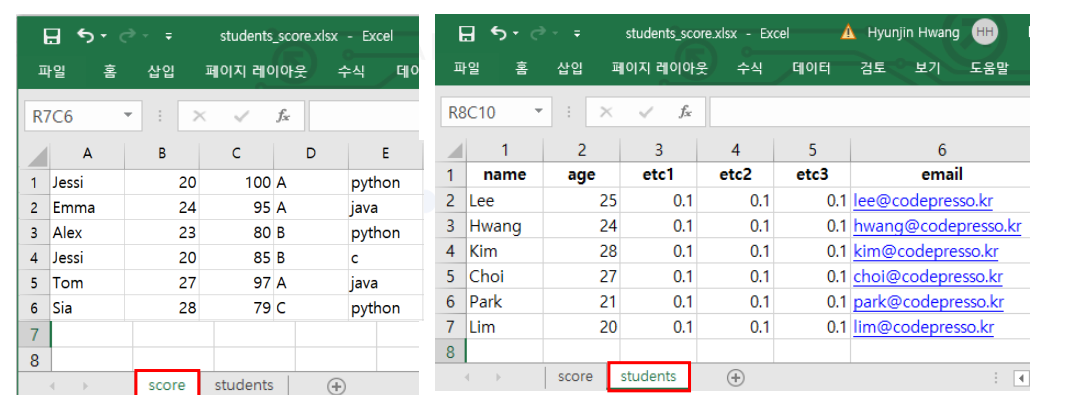
4 Sia 28 79 C python결과를 보면 column인덱스가 이상한 것을 확인할 수 있다. 다른 행의 데이터와 비슷한 것을 보아 이는 column 인덱스가 명시되어 있지 않은 excel 파일임을 추측할 수 있다. (물론 위의 사진에서 보았을 때 score sheet에서 column 인덱스가 없는 것을 확인할 수 있다.)
이를 통해 read_excel()은 별도의 column 데이터가 존재하지 않는 경우 첫번째 데이터가 coluimn index로 설정되는 것을 확인할 수 있다.
# 예시 코드 header 파라미터 활용
import pandas as pd
url = 'https://codepresso-online-platform-public.s3.ap-northeast-2.amazonaws.com/learning-resourse/python-data-analysis/students_score.xlsx'
print('\nRead students_score.xlsx')
sample_df = pd.read_excel(url)
print(sample_df)
#header 파라이터 값을 2로 지정하여 인덱스가 2인 행부터 읽어오도록한다.
sample_df = pd.read_excel(url, header=2)
#column 인덱스를 지정
sample_df.columns = ['name', 'age', 'score', 'grade', 'subject']
print('\nRead Excel by header=none')
print(sample_df)Read students_score.xlsx
Jessi 20 100 A python
0 Emma 24 95 A java
1 Alex 23 80 B python
2 Jessi 20 85 B c
3 Tom 27 97 A java
4 Sia 28 79 C python
Read Excel by header=none
name age score grade subject
0 Jessi 20 85 B c
1 Tom 27 97 A java
2 Sia 28 79 C python
# 예시 코드 sheet 파라미터를 활용하여 다른 sheet 데이터 읽어오기
import pandas as pd
url = 'https://codepresso-online-platform-public.s3.ap-northeast-2.amazonaws.com/learning-resourse/python-data-analysis/students_score.xlsx'
print('\nRead Excel on students sheet')
student_df = pd.read_excel(url,sheet_name='students')
print(student_df)Read Excel on students sheet
name age etc1 etc2 etc3 email
0 Lee 25 0.1 0.1 0.1 lee@codepresso.kr
1 Hwang 24 0.1 0.1 0.1 hwang@codepresso.kr
2 Kim 28 0.1 0.1 0.1 kim@codepresso.kr
3 Choi 27 0.1 0.1 0.1 choi@codepresso.kr
4 Park 21 0.1 0.1 0.1 park@codepresso.kr
5 Lim 20 0.1 0.1 0.1 lim@codepresso.kr
'공부한 것들.. > Pandas' 카테고리의 다른 글
| Pandas 인덱싱(Indexing) & 슬라이싱(Slicing) (0) | 2024.09.14 |
|---|---|
| Pandas 결측치 이해 및 결측치 처리 (2) | 2024.09.14 |
| Pandas DataFrame 데이터 추가 및 삭제 (0) | 2024.09.13 |
| Pandas 데이터 조회 및 변경 (0) | 2024.09.13 |
| Pandas 수치형 데이터 & 범주형 데이터 활용 (0) | 2024.09.13 |



