코드 프레소 [파이썬으로 배우는 데이터 분석 : Pandas] 강의 내용 정리
# 결측치란 ..?
결측치는 누락된 값을 의미하며 Null, None, Na, NaN등으로 표기된다.
결측치 발생의 원인으로는 아래와 같다.
- 수집의 오류
- 기록의 오류
- 미응답
- ..etc
데이터에서 결측치는 언제든 생성될 수 있는 것이고 이를 데이터의 손실 없이 잘 처리하는 방법을 아는 것이 중요하다.
데이터에 존재하는결측치를 처리하는 방법을 정리하면 아래와 같다.
- List-wise deletion (리스트 전체 삭제): 결측값이 하나 이상 포함된 데이터를 모두 제거
- Pairwise deletion (단일 값 삭제) : 결측치 단일값 삭제
- Simple Imputation (단순 대체법) :해당 변수의 나머지 값들의 대표값(mean, median, mode)으로 대체
- Predictive Imputation (예측값 대체법) : 통계, 머신러닝 등을 활용하여 예측 모델 기반 도출된 예측값으로 결측치 대체
결측치를 무작정 제거하거나 임의의 값으로 대체한다면 ..
- 데이터가 너무 편향되는 문제가 발생
- 데이터 개수가 분석 불가 수준으로 작아지는 문제 발생 가능성
따라서, 결측치 발생 원인을 분석하고 그에 따른 적절한 결측치 처리 방법을 찾는 것이 중요하다.
# 결측치 처리..?
Pandas 라이브러리에서 데이터에서 결측값을 조회 및 처리할 수 있는 다양한 함수와 옵션을 제공한다.
데이터에서 결측치를 조회하는 함수는 아래와 같다.
- df.info()
- df.isnull()
- df.isnull().sum()
데이터에서 결측치를 처리하는 함수는 아래와 같다.
- df.dropna()
- df.fillna()
결측치 조회와 처리 방법에 사용할 수 있는 함수를 API Reference를 통해 활용방안을 확인학고 예시코드로 이를 이해해보겠다.
# API Reference
# 결측치 조회 :: pandas.DataFrame.info
API Reference:: pandas.DataFrame.info()

# parameter 정리
- verbose (bool, optional): 전체 요약을 출력할지 여부를 결정한다. 기본적으로 pandas.options.display.max_info_columns 설정을 따른다. True로 설정하면 상세한 정보가 출력된다.
- buf (writable buffer, defaults to sys.stdout): 출력할 대상. 기본적으로 출력은 sys.stdout에 출력된다. 출력 내용을 추가로 처리하려면 쓰기 가능한 버퍼를 전달한다.
- max_cols (int, optional): 열 수가 max_cols를 넘으면 출력이 상세 모드에서 축약 모드로 전환된다. 기본적으로 pandas.options.display.max_info_columns 설정을 따른다.
- memory_usage (bool, str, optional): DataFrame 요소(인덱스 포함)의 메모리 사용량을 표시할지 여부를 지정한다. 기본적으로 pandas.options.display.memory_usage 설정을 따른다.
- True: 메모리 사용량을 항상 표시.
- False: 메모리 사용량을 표시하지 않음.
- 'deep': 심층 메모리 사용량 계산을 수행하며, 이는 더 많은 계산 리소스를 요구하지만 더 정확한 메모리 사용량을 제공한다.
- show_counts (bool, optional): null이 아닌 값의 개수를 표시할지 여부를 결정한다. 기본적으로 DataFrame이 pandas.options.display.max_info_rows와 pandas.options.display.max_info_columns보다 작을 때만 표시된다. True는 항상 개수를 표시하고, False는 개수를 표시하지 않는다.
# 예시코드
import pandas as pd
import numpy as np
# 실습 데이터 생성
df = pd.DataFrame(data = np.arange(18).reshape(6,3),
index = ['a','b','c','d','e','f'],
columns=['col1','col2','col3'])
df['col4'] = pd.Series(data = [1.7, 1.2, 2.4],
index = ['a','e','c'])
df.loc['c'] = None
print('Sample Data')
print(df)
# df.info() 함수로 결측치 유무 확인
print('\n#1 Summary of DataFrame')
print(df.info())Sample Data
col1 col2 col3 col4
a 0.0 1.0 2.0 1.7
b 3.0 4.0 5.0 NaN
c NaN NaN NaN NaN
d 9.0 10.0 11.0 NaN
e 12.0 13.0 14.0 1.2
f 15.0 16.0 17.0 NaN
#1 Summary of DataFrame
<class 'pandas.core.frame.DataFrame'>
Index: 6 entries, a to f
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 col1 5 non-null float64
1 col2 5 non-null float64
2 col3 5 non-null float64
3 col4 2 non-null float64
dtypes: float64(4)
memory usage: 412.0+ bytes
None
# 결측치 조회 :: pandas.DataFrame.isnull
API Reference:: pandas.DataFrame.isnull()
# 예시코드 :: pandas.DataFrame.isnull
import pandas as pd
import numpy as np
# 실습 데이터 생성
df = pd.DataFrame(data = np.arange(18).reshape(6,3),
index = ['a','b','c','d','e','f'],
columns=['col1','col2','col3'])
df['col4'] = pd.Series(data = [1.7, 1.2, 2.4],
index = ['a','e','c'])
df.loc['c'] = None
print('Sample Data')
print(df)
#df.isnull() 함수로 결측치 유무 확인하기
print('\n#2 isnull of DataFrame')
print(df.isnull())Sample Data
col1 col2 col3 col4
a 0.0 1.0 2.0 1.7
b 3.0 4.0 5.0 NaN
c NaN NaN NaN NaN
d 9.0 10.0 11.0 NaN
e 12.0 13.0 14.0 1.2
f 15.0 16.0 17.0 NaN
#2 isnull of DataFrame
col1 col2 col3 col4
a False False False False
b False False False True
c True True True True
d False False False True
e False False False False
f False False False True
# 예시코드 :: pandas.DataFrame.isnull.sum()을 활용해 행, 열 별로 결측값 합 확인
import pandas as pd
import numpy as np
# 실습 데이터 생성
df = pd.DataFrame(data = np.arange(18).reshape(6,3),
index = ['a','b','c','d','e','f'],
columns=['col1','col2','col3'])
df['col4'] = pd.Series(data = [1.7, 1.2, 2.4],
index = ['a','e','c'])
df.loc['c'] = None
print('Sample Data')
print(df)
'''
df.isnull().sum() 함수로 결측치 유무 확인하기
'''
print('\n#4 Sum of all missing values per columns')
print(df.isnull().sum())
'''
df.isnull().sum() 함수에서 데이터 집계 방향 바꾸기
'''
print('\n#5 Sum of all missing values per rows')
print(df.isnull().sum(axis=1))Sample Data
col1 col2 col3 col4
a 0.0 1.0 2.0 1.7
b 3.0 4.0 5.0 NaN
c NaN NaN NaN NaN
d 9.0 10.0 11.0 NaN
e 12.0 13.0 14.0 1.2
f 15.0 16.0 17.0 NaN
#4 Sum of all missing values per columns
col1 1
col2 1
col3 1
col4 4
dtype: int64
#5 Sum of all missing values per rows
a 0
b 1
c 4
d 1
e 0
f 1
dtype: int64
# 결측치 처리 :: pandas.DataFrame.dropna
API Reference:: pandas.DataFrame.dropna()

# parameter 정리
- axis {0 또는 'index', 1 또는 'columns'}, 기본값 0: 누락된 값을 포함하는 행 또는 열을 제거할지 여부를 결정한다.
- 0 또는 'index': 누락된 값을 포함하는 행을 삭제한다.
- 1 또는 'columns': 누락된 값을 포함하는 열을 삭제한다. 단일 축만 허용된다.
- how {'any', 'all'}, 기본값 'any': DataFrame에서 행 또는 열을 삭제할 때, 하나 이상의 NA 값이 있거나 모든 값이 NA인 경우를 결정한다.
- 'any': NA 값이 하나라도 있으면 해당 행 또는 열을 삭제한다.
- 'all': 모든 값이 NA일 때만 해당 행 또는 열을 삭제한다.
- thresh (int, 선택 사항): NA가 아닌 값이 특정 개수 이상 있어야 한다. 이 옵션은 how와 함께 사용할 수 없다.
- subset (열 레이블 또는 레이블 시퀀스, 선택 사항): 다른 축을 따라 고려할 레이블을 지정한다. 예를 들어, 행을 삭제할 때 포함할 열 목록을 지정할 수 있다.
- inplace (bool, 기본값 False): 새로운 DataFrame을 생성하는 대신, 원래 DataFrame을 수정할지 여부를 결정한다.
- ignore_index (bool, 기본값 False): True로 설정하면 결과 축이 0, 1, ..., n-1로 라벨링된다.
# 예시코드:: dropna parameter 'how'활용하여 전체 데이터 중 결측값 삭제
import pandas as pd
import numpy as np
# 실습 데이터 생성
df = pd.DataFrame(data = np.arange(18).reshape(6,3),
index = ['a','b','c','d','e','f'],
columns=['col1','col2','col3'])
df['col4'] = pd.Series(data = [1.7, 1.2, 2.4],
index = ['a','e','c'])
df.loc['c'] = None
print('Sample Data')
print(df)
'''
1) 행을 기준으로 결측치 조회하여 제거하기
2) how=all 인자로 전체 nan 인 경우만 제거하기
'''
print('\n#1 Remove missing values')
print(df.dropna(how='all'))Sample Data
col1 col2 col3 col4
a 0.0 1.0 2.0 1.7
b 3.0 4.0 5.0 NaN
c NaN NaN NaN NaN
d 9.0 10.0 11.0 NaN
e 12.0 13.0 14.0 1.2
f 15.0 16.0 17.0 NaN
#1 Remove missing values
col1 col2 col3 col4
a 0.0 1.0 2.0 1.7
b 3.0 4.0 5.0 NaN
d 9.0 10.0 11.0 NaN
e 12.0 13.0 14.0 1.2
f 15.0 16.0 17.0 NaN# 예시코드:: dropna parameter 'inplace'활용하여 원본 데이터에 적용
import pandas as pd
import numpy as np
# 실습 데이터 생성
df = pd.DataFrame(data = np.arange(18).reshape(6,3),
index = ['a','b','c','d','e','f'],
columns=['col1','col2','col3'])
df['col4'] = pd.Series(data = [1.7, 1.2, 2.4],
index = ['a','e','c'])
df.loc['c'] = None
print('Sample Data')
print(df)
'''
원본 데이터에 반영하기
주석(#)을 지우고, 주어진 빈칸의 코드를 완성하세요.
'''
print('\n#2 Remove missing values with inplace=True')
df.dropna(how='all', inplace=True)
print(df)Sample Data
col1 col2 col3 col4
a 0.0 1.0 2.0 1.7
b 3.0 4.0 5.0 NaN
c NaN NaN NaN NaN
d 9.0 10.0 11.0 NaN
e 12.0 13.0 14.0 1.2
f 15.0 16.0 17.0 NaN
#2 Remove missing values with inplace=True
col1 col2 col3 col4
a 0.0 1.0 2.0 1.7
b 3.0 4.0 5.0 NaN
d 9.0 10.0 11.0 NaN
e 12.0 13.0 14.0 1.2
f 15.0 16.0 17.0 NaN# 예시코드:: dropna parameter 'columns'활용하여 열방향으로 결측값 제거
import pandas as pd
import numpy as np
# 실습 데이터 생성
df = pd.DataFrame(data = np.arange(18).reshape(6,3),
index = ['a','b','c','d','e','f'],
columns=['col1','col2','col3'])
df['col4'] = pd.Series(data = [1.7, 1.2, 2.4],
index = ['a','e','c'])
df.loc['c'] = None
print('Sample Data')
print(df)
'''
열을 기준으로 결측치 조회하여 제거하기
주석(#)을 지우고, 주어진 빈칸의 코드를 완성하세요.
'''
print('\n#3 Remove missing values in columns')
print(df.dropna(axis='columns'))Sample Data
col1 col2 col3 col4
a 0.0 1.0 2.0 1.7
b 3.0 4.0 5.0 NaN
c NaN NaN NaN NaN
d 9.0 10.0 11.0 NaN
e 12.0 13.0 14.0 1.2
f 15.0 16.0 17.0 NaN
#3 Remove missing values in columns
col1 col2 col3
a 0.0 1.0 2.0
b 3.0 4.0 5.0
d 9.0 10.0 11.0
e 12.0 13.0 14.0
f 15.0 16.0 17.0
# 결측치 처리 :: pandas.DataFrame.fillna
API Reference:: pandas.DataFrame.fillna()
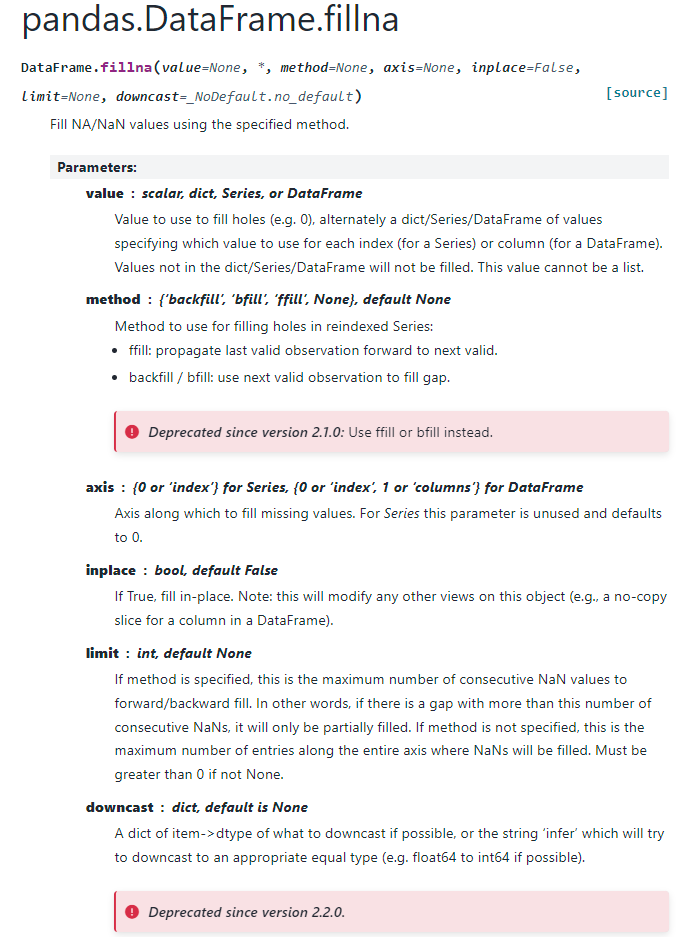
# parameter 정리
- value (scalar, dict, Series, 또는 DataFrame): 결측값을 대체할 값. 예를 들어, 0으로 결측값을 채울 수 있으며, 특정 인덱스(Series) 또는 컬럼(DataFrame)에 대해 채울 값을 지정할 수 있는 dict, Series, 또는 DataFrame도 사용할 수 있다. 리스트는 사용할 수 없다.
- method {'backfill', 'bfill', 'ffill', None}, 기본값 None: 결측값을 채우는 방법을 지정한다.
- 'ffill': 마지막으로 유효한 값을 다음 유효한 값으로 전달하여 채운다.
- 'backfill' 또는 'bfill': 다음 유효한 값을 사용하여 결측값을 채운다.
- axis {0 또는 'index'} for Series, {0 또는 'index', 1 또는 'columns'} for DataFrame: 결측값을 채울 축을 지정한다. Series에서는 기본적으로 axis=0을 사용하며, DataFrame에서는 0은 행, 1은 열을 의미한다.
- inplace (bool, 기본값 False): 원래 객체를 수정할지 여부를 결정한다. True로 설정하면 복사본을 만들지 않고 원래 객체를 수정한다.
- limit (int, 기본값 None): method가 지정된 경우, 연속된 NaN 값 중에서 최대 몇 개까지 채울지 지정한다. 예를 들어, 연속된 NaN 값이 지정된 한계를 넘는 경우 일부만 채워진다. method가 지정되지 않은 경우, 전체 축에 걸쳐 NaN 값을 채울 최대 항목 수를 의미하며, None이 아닌 경우 0보다 커야 한다.
- downcast (dict, 기본값 None): 가능한 경우 항목을 특정 dtype으로 다운캐스팅한다. 예를 들어, float64를 int64로 변환할 수 있다면 변환을 시도한다.
# 예시코드:: fillna 활용하여 결측값 대체
import pandas as pd
import numpy as np
# 실습 데이터 생성
df = pd.DataFrame(data = np.arange(18).reshape(6,3),
index = ['a','b','c','d','e','f'],
columns=['col1','col2','col3'])
df['col4'] = pd.Series(data = [1.7, 1.2, 2.4],
index = ['a','e','c'])
df.loc['c'] = None
df.iloc[:2, 0] = np.nan
df.iloc[:4, 1] = np.nan
print('\nSample Data')
print(df)
'''
결측값을 0 으로 대체
'''
print('\n#4 Replace missing values')
print(df.fillna(0))
'''
딕셔너리를 활용한 컬럼별 대체값 지정
'''
print('\n#5 Replace missing values')
replace_set = {'col2':0, 'col4':100}
print(df.fillna(replace_set))Sample Data
col1 col2 col3 col4
a NaN NaN 2.0 1.7
b NaN NaN 5.0 NaN
c NaN NaN NaN NaN
d 9.0 NaN 11.0 NaN
e 12.0 13.0 14.0 1.2
f 15.0 16.0 17.0 NaN
#4 Replace missing values
col1 col2 col3 col4
a 0.0 0.0 2.0 1.7
b 0.0 0.0 5.0 0.0
c 0.0 0.0 0.0 0.0
d 9.0 0.0 11.0 0.0
e 12.0 13.0 14.0 1.2
f 15.0 16.0 17.0 0.0
# 예시코드:: fillna 활용하여 결측값 대체
import pandas as pd
import numpy as np
# 실습 데이터 생성
df = pd.DataFrame(data = np.arange(18).reshape(6,3),
index = ['a','b','c','d','e','f'],
columns=['col1','col2','col3'])
df['col4'] = pd.Series(data = [1.7, 1.2, 2.4],
index = ['a','e','c'])
df.loc['c'] = None
df.iloc[:2, 0] = np.nan
df.iloc[:4, 1] = np.nan
print('\nSample Data')
print(df)
'''
1)대표값인 평균을 활용하여 결측치 대체
2)원본 데이터에 반영
'''
print('\n#6 Replace missing values')
replace_set = {'col1':df['col1'].mean()}
df.fillna(replace_set, inplace=True)
print(df)Sample Data
col1 col2 col3 col4
a NaN NaN 2.0 1.7
b NaN NaN 5.0 NaN
c NaN NaN NaN NaN
d 9.0 NaN 11.0 NaN
e 12.0 13.0 14.0 1.2
f 15.0 16.0 17.0 NaN
#6 Replace missing values
col1 col2 col3 col4
a 12.0 NaN 2.0 1.7
b 12.0 NaN 5.0 NaN
c 12.0 NaN NaN NaN
d 9.0 NaN 11.0 NaN
e 12.0 13.0 14.0 1.2
f 15.0 16.0 17.0 NaN'공부한 것들.. > Pandas' 카테고리의 다른 글
| Pandas 집계함수 (0) | 2024.09.14 |
|---|---|
| Pandas 인덱싱(Indexing) & 슬라이싱(Slicing) (0) | 2024.09.14 |
| Pandas 데이터 파일 읽기 (1) | 2024.09.14 |
| Pandas DataFrame 데이터 추가 및 삭제 (0) | 2024.09.13 |
| Pandas 데이터 조회 및 변경 (0) | 2024.09.13 |



