# Numpy ndarray shape 변경..?
머신 러닝을 알고리즘 적용을 위해서나 이미지 데이터를 딥러닝에 적용시 등의 사례에서 볼 수 있듯이 각 알고리즘에서 정해진 ndarray의 shape에 맞게 각 데이터의 shape 변경이 필요하다.
다음은 numpy의 ndarray의 shaep을 변경하는 방법을 나엻한 것이다.
- numpy.reshape()
- numpy.resize()
- numpy.newaxis
- numpy.squeeze()
다른 shape 변경을 위한 함수가 많이 존재하지만 대표적으로 위의 함수를 정리하도록 하겠다.
# 각 함수의 API Reference 정리 예시 코드
# numpy.reshape()
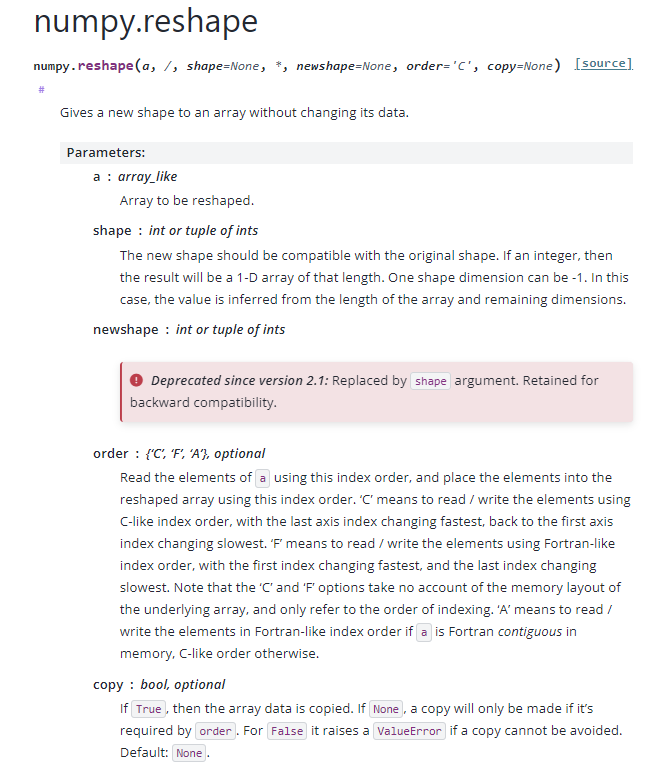
API Reference :: numpy.reshape()
# 파라미터 정리
- a (array_like) : 변형할 배열을 의미한다.
- shape : 정수 또는 정수들의 튜플로, 새 배열의 형태를 정의한다. 원래 배열의 형태와 호환 가능해야 한다. 정수 하나로 입력되면, 해당 길이의 1차원 배열을 반환한다. 하나의 차원을 -1로 지정할 수 있으며, 이 경우 배열의 길이와 나머지 차원들로부터 값을 추론한다.
- newshape : 버전 2.1부터 사용되지 않으며, shape 파라미터로 대체되었다. 하위 호환성을 위해 유지된다.
- order: 배열의 요소를 읽고 쓸 때 사용할 인덱스 순서를 지정한다.
- 'C' : C 언어 방식의 인덱스 순서로, 마지막 축의 인덱스가 가장 빠르게 변한다.
- 'F' : Fortran 방식의 인덱스 순서로, 첫 번째 축의 인덱스가 가장 빠르게 변한다.
- 'A' : 배열 a가 메모리에서 Fortran 방식으로 연속적이면 Fortran 순서로, 그렇지 않으면 C 순서로 처리한다.
- copy : True일 경우 배열 데이터를 복사한다. None일 경우 order에 따라 복사가 필요한 경우에만 복사한다. False일 경우, 복사를 피할 수 없으면 ValueError를 발생시킨다. 기본값은 None이다.
#예시코드
import numpy as np
def printinfo(arr):
print(arr)
print("shape:: {}, size::{} dtype::{} dimension::{}"
.format(arr.shape, arr.size, arr.dtype, arr.ndim))
origin_data = np.arange(1,16,1)
print("Origin Data :: ")
printinfo(origin_data)
reshaped_data = origin_data.reshape((3,5))
print("Reshaped Data :: ")
printinfo(reshaped_data)
# reshape(-1,N) 활용:: 기존 데이터를 유지하면서 shape를 변경하는 방식
reshaped_data2 = origin_data.reshape((-1,5))
print("\nReshaped Data using -1 arg :: ")
printinfo(reshaped_data2)
print("\nOrigin Data :: ")
printinfo(origin_data)Origin Data ::
[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
shape:: (15,), size::15 dtype::int64 dimension::1
#설정한 크기로 변경 가능하다.
Reshaped Data ::
[[ 1 2 3 4 5]
[ 6 7 8 9 10]
[11 12 13 14 15]]
shape:: (3, 5), size::15 dtype::int64 dimension::2
#-1을 reshape의 크기에 활용하면 원본 데이터의 크기에 따라 정확하게 설정 가능하다.
Reshaped Data using -1 arg ::
[[ 1 2 3 4 5]
[ 6 7 8 9 10]
[11 12 13 14 15]]
shape:: (3, 5), size::15 dtype::int64 dimension::2
#기존 데이터는 변경되지 않는 겻을 확인할 수 있다.
Origin Data ::
[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
shape:: (15,), size::15 dtype::int64 dimension::1# numpy.resize()
API Reference :: numpy.resize()

# 파라미터 정리
- a (array_like : 변형할 배열을 의미한다.
- shape : 정수 또는 정수들의 튜플로, 새 배열의 형태를 정의한다. 원래 배열의 형태와 호환 가능해야 한다. 정수 하나로 입력되면, 해당 길이의 1차원 배열을 반환한다. 하나의 차원을 -1로 지정할 수 있으며, 이 경우 배열의 길이와 나머지 차원들로부터 값을 추론한다.
numpy.resize()는 numpy.reshape()와 달리 원본 데이터의 크기를 바꾼다. 또한, 반환값이 없다.
# 예시 코드
import numpy as np
def printinfo(arr):
print(arr)
print("shape:: {}, size::{} dtype::{} dimension::{}"
.format(arr.shape, arr.size, arr.dtype, arr.ndim))
origin_data = np.arange(1,16,1)
print("Origin Data :: ")
printinfo(origin_data)
#배열의 크기가 변하는 것을 확인
origin_data.resize((3,5))
print("\nResized Data :: ")
printinfo(origin_data)
#원본 데이터 보다 작은 크기로 설정하면 요소들이 제거됨을 확인
origin_data.resize((2,5))
print("\nResized Data :: ")
printinfo(origin_data)
#원본 데이터 보다 큰 크기로 설정하면 요소가 추가됨을 확인
origin_data.resize((4,5))
print("\nResized Data :: ")
printinfo(origin_data)Origin Data ::
[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
shape:: (15,), size::15 dtype::int64 dimension::1
Resized Data ::
[[ 1 2 3 4 5]
[ 6 7 8 9 10]
[11 12 13 14 15]]
shape:: (3, 5), size::15 dtype::int64 dimension::2
Resized Data ::
[[ 1 2 3 4 5]
[ 6 7 8 9 10]]
shape:: (2, 5), size::10 dtype::int64 dimension::2
Resized Data ::
[[ 1 2 3 4 5]
[ 6 7 8 9 10]
[ 0 0 0 0 0]
[ 0 0 0 0 0]]
shape:: (4, 5), size::20 dtype::int64 dimension::2
import numpy as np
def printinfo(arr):
print(arr)
print("shape:: {}, size::{} dtype::{} dimension::{}"
.format(arr.shape, arr.size, arr.dtype, arr.ndim))
# reshape(-1,N) 활용:: 기존 데이터를 유지하면서 shape를 변경하는 방식
origin_data.resize((-1,3))
print("\nReshaped Data using -1 arg :: ")
printinfo(origin_data)
# numpy.newaxis
np.newaxis를 사용하면 배열에 새로운 차원을 추가할 수 있다.
# 예시코드
import numpy as np
arr = np.array([1, 2, 3])
arr_new = arr[:, np.newaxis] # 2차원 배열로 변환
print(arr_new)
print("Shape :: ", arr_new.shape)
arr_new_new = arr_new[:,np.newaxis] #3차원 배열로 변환
print("\n",arr_new_new)
print("Shape :: ", arr_new_new.shape)[[1]
[2]
[3]]
Shape :: (3, 1)
[[[1]]
[[2]]
[[3]]]
Shape :: (3, 1, 1)# numpy.squeeze()
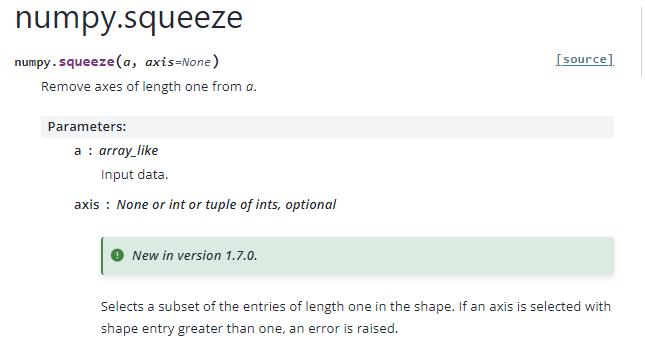
API Reference :: numpy.squeez()
# 파라미터 정리
- a (array_like : 변형할 배열을 의미한다.
- axis: None 또는 정수, 정수들의 튜플
numpy.squeeze()는 배열의 차원중 길이가 1 인 차원을 제거한다. 선택한 축의 길이가 1보다 크면 오류가 발생한다.
# 예시 코드
import numpy as np
arr = np.array([1, 2, 3])
arr_new = arr[:, np.newaxis] # 2차원 배열로 변환
print(arr_new)
print("Shape :: ", arr_new.shape)
arr_new_new = arr_new[:,np.newaxis] #3차원 배열로 변환
print("\n",arr_new_new)
print("Shape :: ", arr_new_new.shape)
squeezed_arr = arr_new_new.squeeze() # numpy.squeeze()를 통해 길이가 1인 차원 축소
print("\nSqueezed arr :: ")
print(squeezed_arr)
print("\n",squeezed_arr.shape)
[[1]
[2]
[3]]
Shape :: (3, 1)
[[[1]]
[[2]]
[[3]]]
Shape :: (3, 1, 1)
# 길이가 1인 차원이 축소되어 (3,)인 shape을 갖는 것을 볼 수 있다
Squeezed arr ::
[1 2 3]
(3,)
# numpy.transpose()
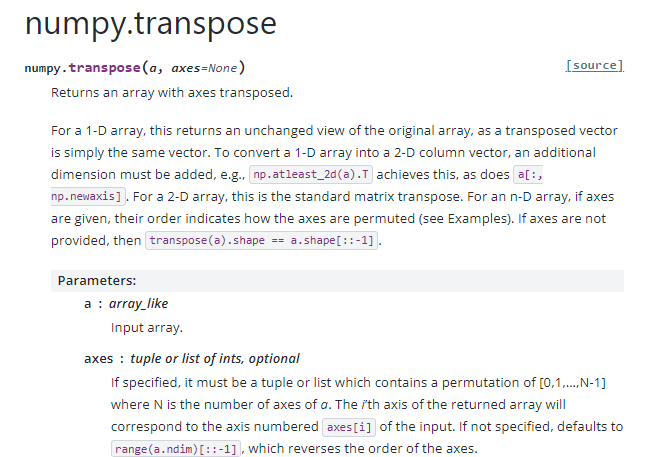
API Reference :: numpy.transpose()
# 파라미터 정리
- a (array_like) : 변형할 배열을 의미한다.
- axes: 지정된 경우, 이는 [0, 1, ..., N-1]의 순열을 포함하는 튜플 또는 리스트여야 한다. 여기서 N은 배열 a의 축 개수이다. 반환된 배열의 i번째 축은 입력 배열에서 axes[i]로 번호가 매겨진 축에 해당한다. 지정되지 않으면 기본적으로 range(a.ndim)[::-1]이 사용되며, 이는 축의 순서를 반대로 정렬한다.
#예시코드
import numpy as np
arr = np.arange(1,10,1)
arr.resize((3,3))
print("arr :: ")
print(arr)
transposed_arr = np.transpose(arr)
print("\nTransposed arr :: ")
print(transposed_arr)
a = np.ones((1, 2, 3))
print("\nA :: ")
print(a)
print("Shape :: " , a.shape)
## axe parameter
transposed_a = np.transpose(a, (1, 0, 2))
print("\nTransposed A :: ")
print(transposed_a)
print("Shape transposed A :: ", transposed_a.shape)
arr ::
[[1 2 3]
[4 5 6]
[7 8 9]]
Transposed arr ::
[[1 4 7]
[2 5 8]
[3 6 9]]
A ::
[[[1. 1. 1.]
[1. 1. 1.]]]
Shape :: (1, 2, 3)
Transposed A ::
[[[1. 1. 1.]]
[[1. 1. 1.]]]
Shape transposed A :: (2, 1, 3)
#shape를 살펴보면 0 ,1 ,2 에 해당하는 shape값이 인자로 입력한 것과 같이 1, 0, 2로 변한 것을 볼 수 있다.
'공부한 것들.. > Numpy' 카테고리의 다른 글
| Numpy 집계 함수 (0) | 2024.09.12 |
|---|---|
| Numpy 기본 연산 (0) | 2024.09.12 |
| Numpy :: 데이터 타입 (0) | 2024.09.12 |
| Numpy 자료구조:: ndarray 생성 (2) | 2024.09.11 |
| Numpy 자료구조 :: ndarray (N- Dimension Array) (0) | 2024.09.09 |



